Intent at a Glance: Gaze-Guided Robotic Manipulation via Foundation Models
Tracey Yee Hsin Tay♡,
Xu Yan*,
Jonathan Ouyang*,
Daniel Wu,
William Jiang,
Jonathan Kao,
Yuchen Cui† The University of California, Los Angeles
♡ Work done as an exchange student at UCLA.
* Equal contribution.
† Corresponding Author.
Abstract
Designing intuitive interfaces for robotic control remains a central challenge in enabling effective human-robot interaction, particularly in assistive care settings. Eye gaze offers a fast, non-intrusive, and intent-rich input modality, making it an attractive channel for conveying user goals. In this work, we present GAMMA (Gaze Assisted Manipulation for Modular Autonomy), a system that leverages ego-centric gaze tracking and a vision-language model to infer user intent and autonomously execute robotic manipulation tasks. By contextualizing gaze fixations within the scene, the system maps visual attention to high-level semantic understanding, enabling skill selection and parameterization without task-specific training. We evaluate GAMMA on a range of table-top manipulation tasks and compare it against baseline gaze-based control without reasoning. Results demonstrate that GAMMA provides robust, intuitive, and generalizable control, highlighting the potential of combining foundation models and gaze for natural and scalable robot autonomy.
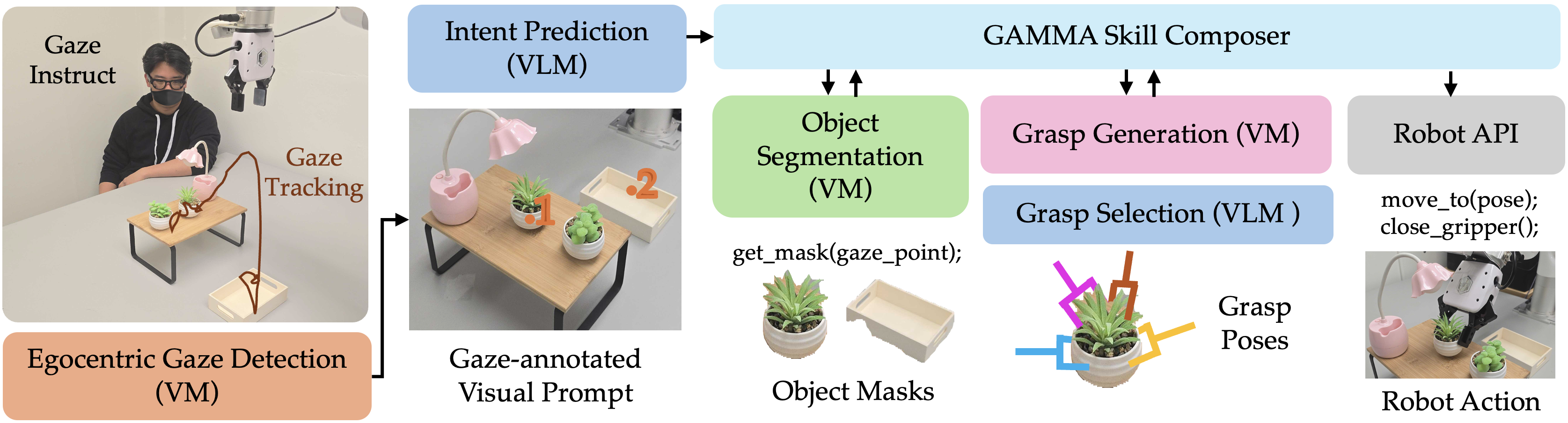
Overview of GAMMA. A user wearing smart glasses uses their gaze to specify a manipulation task. In this example, the user wants the robot to pick up a plant under the lamp and place it in a tray. GAMMA transforms the gaze fixations into the robot's view and prompts the VLM to predict user intent. Given the predicted user intent, GAMMA calls corresponding functions for perception, planning, and execution. GAMMA prompts a VLM to select a proper grasping pose that takes the task context into consideration (e.g., not colliding with the lamp).
Method
Functional Modules of GAMMA. GAMMA consists of various sensing & perception modules that leverage pretrained vision models, and VLM-based reasoning modules.
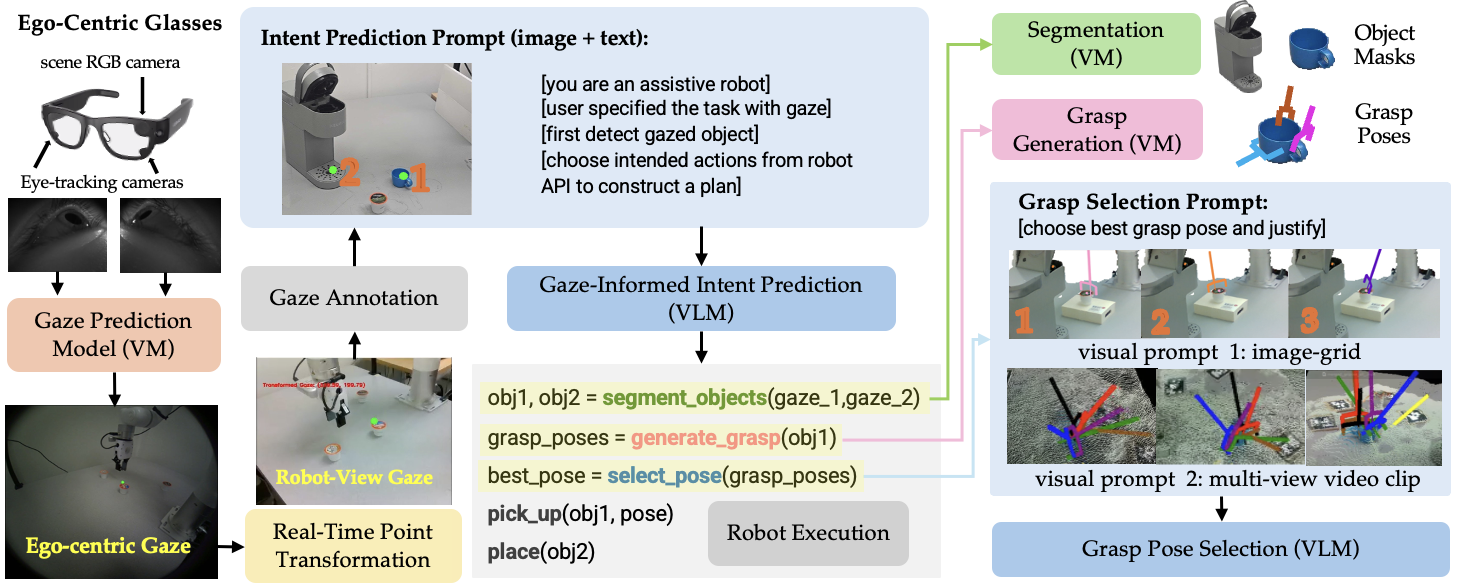
We introduce GAMMA (Gaze Assisted Manipulation for Modular Autonomy), a robotic manipulation system leveraging gaze-tracking combined with vision-language foundation models (VLMs). The user's gaze points, captured by wearable smart glasses, are mapped onto the robot's perspective. VLMs interpret these gaze points to predict user intent, generating appropriate robotic commands for perception, planning, and task execution. GAMMA utilizes pretrained models to achieve zero-shot generalization without task-specific training, enabling flexible and scalable robotic autonomy.
GAMMA
GAMMA integrates real-time gaze tracking from Meta's Project Aria glasses, transforming egocentric gaze data into actionable insights. It leverages SAM2 for object segmentation and Contact-GraspNet for grasp prediction, augmented by multi-viewpoint grasp validation. High-level task inference and context-aware grasp selection are performed by specialized VLMs, employing chain-of-thought reasoning prompted through visual and textual cues.
Gaze-based Intent Reasoning Tasks. (Top) We designed 30 tabletop manipulation scenarios in lab for intent reasoning with diverse difficulty levels. Easy scenes are relatively clean, medium difficulty-level scenes are cluttered or contain longer sequences of gaze points. The hard cases involve visual attacks. (Bottom) We also randomly sampled 45 scenes from the DROID dataset containing in-the-wild manipulation tasks and annotated the scenes for intent reasoning.
Task / VLM
Gemini2.0F
Gemini2.5F
Gemini Pro
Llama4-Maverick
GPT-4o
Lab-Tabletop
0.93
0.91
0.94
0.75
0.78
Wild (DROID)
0.64
0.67
0.73
0.37
0.73
Average
0.79
0.79
0.84
0.56
0.76
VLM inference accuracies for predicting user intent. For Lab-Tabletop tasks, each intent involves a sequence of actions and corresponding objects (e.g., pick up nail polish, place in basket). For Wild tasks, each intent is a natural language description.
Intent Recognition Prompt
You are an expert in recognizing objects in the scene and guess what people want to do with these objects.
Given an image, follow the INSTRUCTIONS below to infer what the intent is.
Determine a sequence of the following functions that are necessary to complete the intended task.
Include the appropriate gaze point numbers as parameters into the function.
INSTRUCTIONS:
1. Input description: There will be red dots marked with numbers in the images. The number represents the order of the red dots.
2. Detect which objects the dots are exactly on.
- You have to choose an object for each dot from the object pool: [watering can, yellow beaker, potted plant, basket, flip-top candy, drawer, box, wooden shelf, table, jar-shaped nail polish, coffee maker, coffee pod, cup]
- It is possible that objects are the same.
- If you think the dot is on the background table surface, select an object that is closest to the dot.
- If you are not sure, just give your best guess.
3. Choose an action that is mostly reasonably happening between the two detected objects.
- You have to choose an action from the action pool: [pick_and_place, pouring]
4. Output description: You MUST output ONLY 1 sentence in the specified format as a STRING: "action: selected_action, 1: object_name_1, 2: object_name_2"
EXAMPLE:
Input: An image with 2 dots in the image. Dot number 1 is on a basket and dot number 2 is on a bread.
Your thinking process should be:
- First, you will detect that dot 1 is on "bread" and dot 2 is on "basket".
- Second, based on "bread" and "basket", the most possible action for them would be "pick_and_place".
- Third, output in the specified dictionary format.
Output:
"action: pick_and_place, 1: bread, 2: basket"
Grasp Selection Visual Prompts. We evaluated with different visual representations for grasp selection. To provide enough information for inferring the 3D grasping poses, we use both numbered multi-view image prompts (top) and a short video clip of a camera hovering around color-coded grasp pose candidates (bottom). Different visual representations resulted in the VLM (Gemini 2.5 Pro) making different predictions.
Prompt / VLM
Gemini2.0F
Gemini2.5F
Gemini Pro
Llama4-Maverick
GPT-4o
Image Average
0.20
0.47
0.60
0.13
0
Image Time (s)
6.42
5.44
24.83
5.41
8.18
Video Average
0.27
0.67
0.47
–
–
Video Time (s)
15.96
15.18
32.06
–
–
VLM grasp selection performance across visual prompts. "–" indicates missing or unsupported data.
Grasp Selection Prompt
You are a pose selector for assisting a robot to grasp an object in pick-and-place tasks.
TASK:
Given a video of a 3D point cloud with 9 possible grasping poses and the pick-and-place task description, follow the INSTRUCTION to select the one pose that most likely to help the robot finish the task successfully.
INSTRUCTIONS:
1. Input description: The video shows a robot arm base, an object to pick, an object to place, and nine potential grasp poses indicated by the coloured rendered arms. A sentence of the task will be provided in format of "Pick the OBJECT_TO_PICK and place it at OBJECT_TO_PLACE."
2. Your goal is to identify the single optimal grasp pose to complete a task, considering the entire environment and the object's properties. Note that the robot end effector cannot change orientation once an object is grabbed. In other words, the grasp pose is the pose that the end effector will be in throughout the entire motion.
3. Observe the scene. Identify the robot arm, the target object, the grasp markers, and *all other objects and significant environmental features* (e.g., containers, fixtures, surfaces, walls, potential obstructions). Note their spatial relationships.
4. Object analysis: Think about the characteristics of the OBJECT_TO_PICK and OBJECT_TO_PLACE, and if OBJECT_TO_PLACE shape suggests a specific orientation for placement.
5. Analyze the environmental constraints and placement/interaction restrictions.
6. Evaluate the given poses from placement feasibility, pick feasibility, and grasp stability.
7. Select the optimal pose: Choose the most stable, collision-free pose that will result in the successful completion of the entire task.
8. Output description: Your response MUST be a single, valid JSON object with "detected_poses", "pose_analysis", "potential_poses", "final_selected_pose" and "justification" sections.
Baseline
The baseline method utilizes a gaze-controlled panel, where users select visual markers on-screen to directly control the robot's 6-DoF arm movements and gripper operations. This method provides direct user control but demands higher cognitive load and interaction time.
Experimental setup. Left: baseline 2D gaze control panel. Right: tasks in user study are of different difficulty levels. The more constrained the picking pose is, the harder the reasoning and execution becomes.
Results
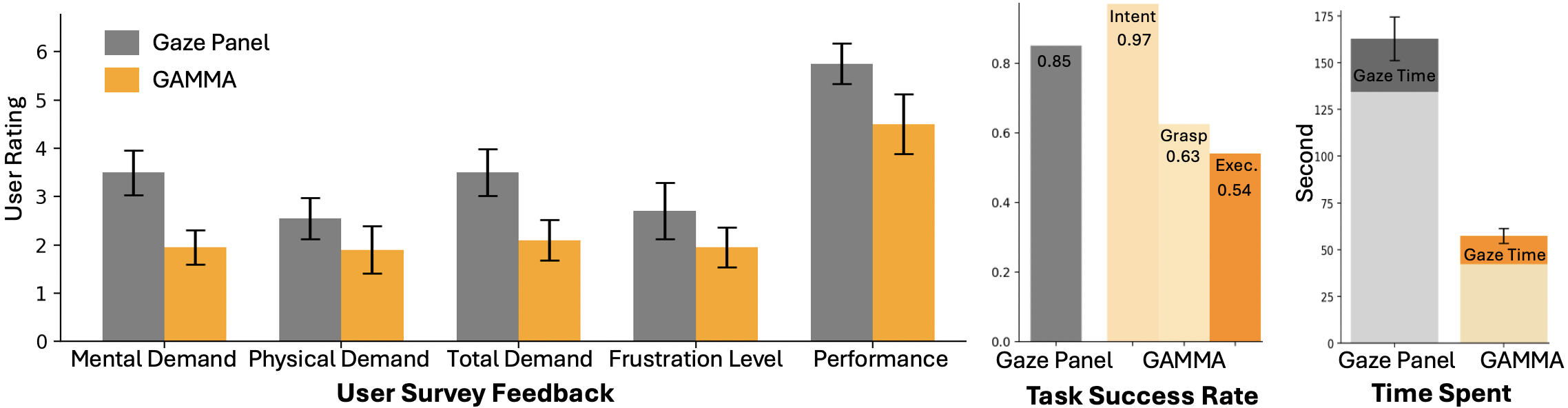
Experimental evaluation demonstrated GAMMA significantly reduced task completion time compared to the gaze-panel baseline, requiring less cognitive and physical effort from users. However, GAMMA showed variability in grasp success due to challenges in precise grasp prediction. While objectively more efficient, user feedback indicated a preference for the baseline method's direct control, highlighting the importance of balancing automation with user agency.
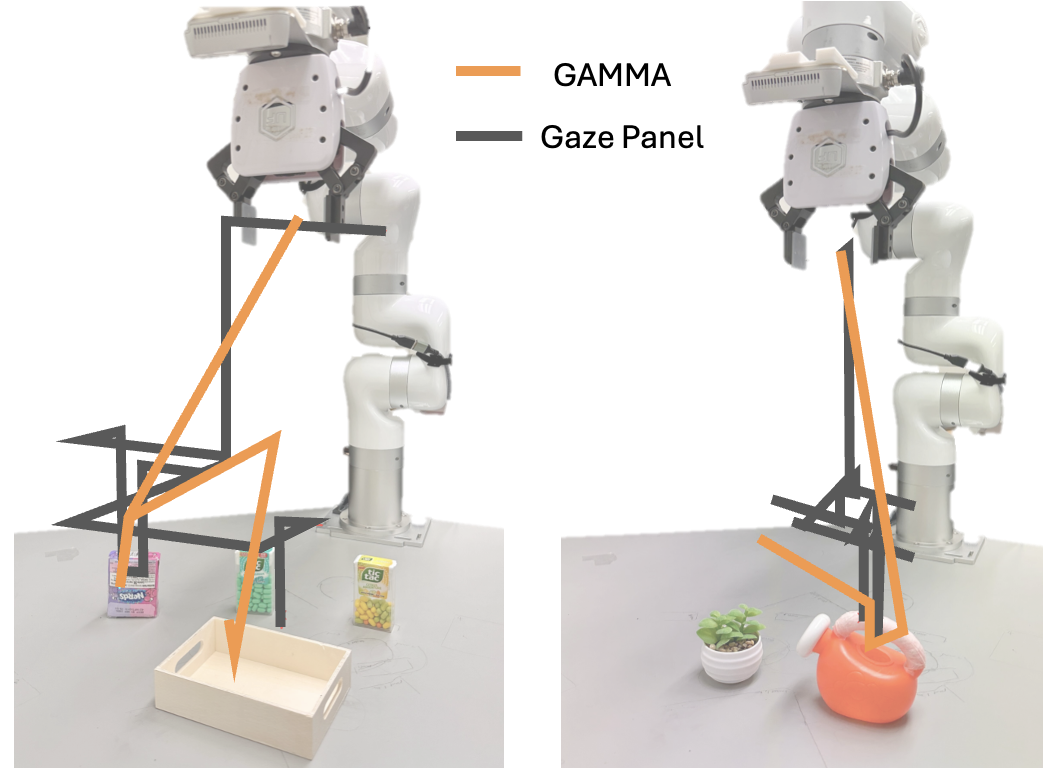
User Study Results. We present the subjective evaluation in average Likert-scale ratings from the users and the objective measure of time spent and success rates. We see that while users consider GAMMA to require lower demand and spent less time on the task, their performance is higher when they have the full control of the robot as GAMMA often requires another trial to correct a wrong prediction.Visualization of sample trajectories. GAMMA trajectories are shorter and cleaner than gaze panel trajectories.
Conclusion
GAMMA presents a promising framework for intuitive and efficient gaze-guided robotic manipulation. By integrating advanced foundation models with real-time gaze tracking, GAMMA achieves robust, scalable autonomy without task-specific training. The user study results underscore a nuanced trade-off between automation efficiency and user preference for direct control, suggesting future work should explore hybrid interfaces that combine intuitive automation with opportunities for user intervention.
BibTeX
@article{gamma,
title = {Intent at a Glance: Gaze-Guided Robotic Manipulation via Foundation Models},
author = {Tracey Yee Hsin Tay and Xu Yan and Jonathan Ouyang and
Daniel Wu and William Jiang and Jonathan Kao and Yuchen Cui},
journal = {arXiv preprint arXiv:2601.05336},
year = {2025}
}